
Continue with More Advanced Python Interview Questions and Answers
Below is the list of MUST Know Python Interview Questions with detailed answers:
- Explain how to make HTTP request in Python?
- Describe how to connect to MongoDB. Explain Basic CRUD operation using Python.
- How does Python handle the memory management?
- Describe the following Data Structure in Python with Example?
- Hashtable
- Dictionary
- Collections
- What are Regular Expressions and how to use them in Python?
- Give some example of Functional programming in Python?
- Describe Python’s Exception Handling mechanism in brief?
- How Object Serialization works in Python?
- Describe Object Oriented feature in Python?
- Python Certification Training
Explain how to make HTTP request in Python?
There are different ways to make http request:
Get Request using httplib2:
Here is an example session that uses the “GET” method:
>>> import httplib2
>>> http = httplib2.Http()
>>> response = http.request("http://edition.cnn.com")[0]
>>> content = http.request("http://edition.cnn.com")[1]
>>> print (response.status, response.reason)
200 OK
>>> print(content.decode())
<!DOCTYPE html><html class="no-js"><head><meta content="IE=edge,chrome=1" http-equiv="X-UA-Compatible"> …………..
>>> sport = http.request("http://edition.cnn.com/sport",
method="GET")[1]Post Request:
Here is an example session that shows how to “POST” requests:
>>> import httplib2, urllib
>>> params = urllib.urlencode({'id': 1, 'name': ‘john’, 'address': ‘dublin’})
>>> headers = {"Content-type": "application/x-www-form-urlencoded",
... "Accept": "application/json"}
>>> http = httplib2.Http()
>>> request = httplib.request("somehost.com:80",method="POST", ...headers={"Content-type": "application/x-www-form-urlencoded",
... "Accept": "application/json"}, body=urllib.parse.urlencode(params))
>>> response = request[0]
>>> print response.status, response.reason
200 OK
>>> content = request[1].decode()
Describe how to connect to MongoDB. Explain Basic CRUD operation using Python.
Install python driver for mongodb with following command:
pip install pymongo
Create a python script with name dbconnect.py as following:
# import python driver
from pymongo import MongoClient
def dbConnect:
client = MongoClient()
client = MongoClient("mongodb://addressbook.net:27017")
db = client.addressbook # addressbook is the database name
# accessing collection
mycollection = db.dataset
- Insert Data with PyMongo
There are two method to insert data to database inser_one() and insert_many() to add data to a collection. If dataset is a collection in addressbook database.
Insert_one:
>>> result = db.dataset.insert_one({'address': ‘140,summertown,london’}) >>> result.inserted_id ObjectId('54e112cefba822406c9cc208') >>> db.dataset.find_one({'address': ‘140,summertown,london’}) {u'address': ‘140,summertown,london’, u'_id': ObjectId('54e112cefba822406c9cc208')}Insert_many:
>>> result = db.dataset.insert_many([{'address': ‘150,summertown,london’},{'address': ‘9,balnchardstown,dublin’}]) >>> db.dataset.count() 3 - Find Document
db.dataset.find_one({'address': ‘140,summertown,london’}) {u'address': ‘140,summertown,london’, u'_id': ObjectId('54e112cefba822406c9cc208')}Use cursor to iterate all the address in the dataset collection of addressbook database:
cursor = db.dataset.find() for address in cursor: print(address)Use cursor to perform logical and operation, this will print all document those have city= london and postcode=10075.
cursor = db.dataset.find({"address.city": "london", "address.zipcode": "10075"}) for address in cursor: print(address)If we want to perform an or operation the cursor would be as following
cursor = db.dataset.find( {"$or": [{"address.city": " london"}, {"address.zipcode": "10075"}]}) - Update data
There are update_one and update_many two method in order to update data:
update_one:
result = db.dataset.update_one( {"address_id": "101"}, {"$set": {"address.street": "9 Coolmine,Dublin"}} )update_many:
result = db.dataset.update_many( {"address.zipcode": "10016", "address.city": "Burlin"}, { "$set": {"address.zipcode": "10016C"}, "$currentDate": {"lastModified": True} } ) - Delete Data
The following command will delete all the address data where city = london.result = db.dataset.delete_many({"city": "london"})
How does Python handle the memory management?
The different type of memory for python are as following:
Memory management is very interesting in python. There are 2 types of object which are
- Primitive object like number or string
- Container object such as dictionary, list or user defined class
Each object has a value, one or more name and reference count. For example, in the following example.
10 is a python object, it has 2 name x and y and the reference count for the object is 2 as two name is referred to the object.
If we execute print(id(x)), it shows the memory location for x which is also the same memory location for y. Therefore x and y both are name for same object ‘10’.
Now if we assign x to z , we can see that the memory location for z is exactly same as x and y which is actually the memory location for 10.
If we execute, print (x is y) => it will print ‘True’, as both x and y is referring to the same object which is 300.
If we execute ‘del x’, it will not delete the object, however the reference count for 300 will be decreased by one.
If we create another object w and give it value ‘car’, it would create a string object and will get different memory location.
If we assign w to z, which was earlier assigned with x , which was a number, z would point to the memory location of w instead of x, and x is z => false.
Heap Memory and Stack Memory:
def main():
x=300
print(id(x))
w=sqr(x)
print(id(w))
def sqr(x):
print (id(x))
z=x*x
print(id(z))
return z
if __name__ == "__main__":
main()In this above example, under main method an object 300 has been referenced with name x. and there is another function has been defined as sqr. For the above example, the output would be:
1036686092944 1036686092944 1036681129680 1036681129680
So in both function main and sqr, the x is referencing to the same memory location. And z as well as w are referencing to the same memory location. When sqr method is returned the reference z is no longer in scope, therefore the reference count of 90000 is reduced to 0 and the returned value is assigned to w and w also referenced to 90000, the reference count to w in increased by 1. Every function is executed on stack memory and each reference is also created in stack memory. However the object is created in heap memory.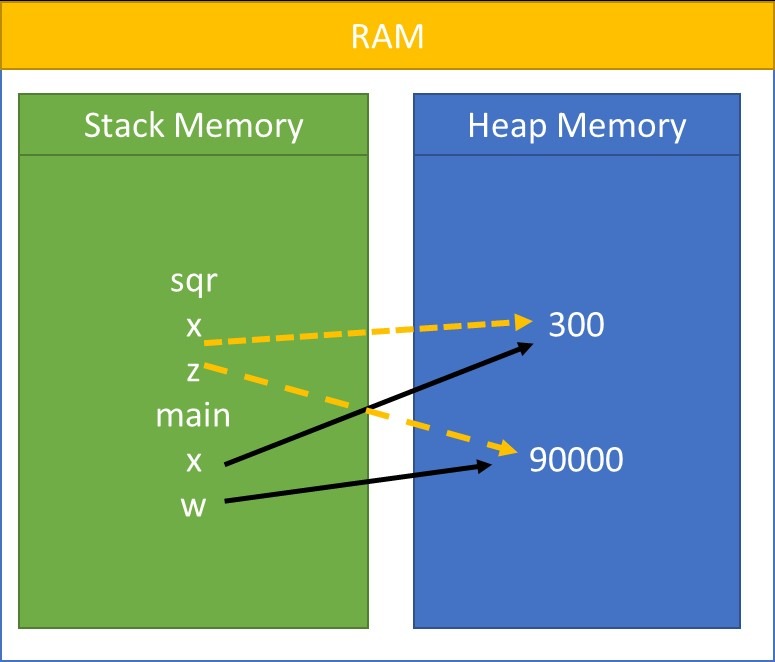
Describe the following Data Structure in Python?
Hashtable:
This is a data structure which stores object as a (key,value) tuple.
hashtable = {}
hashtable[1] = "Summer"
hashtable[2] = "Fall"
hashtable[3] = "Winter"
print(hashtable)The output would be:

Dictionary:
- Dictionary is as an un-ordered set of key: value pairs where keys are unique.
- {} is an empty dictionary.
- The dict() constructor builds dictionaries directly from sequences of key-value pairs.
>>> dict([('a', 1), ('b', 2), ('c', 3),(‘d’,4)]) {'a': 1, 'b': 2, 'c': 3, ‘d’:4} - Indexed by keys instead of range of number; keys can be only immutable e.g number, string or tuple with number, string or tuple; if a tuple is of mutable object that can not be key of a dictionary.
- This can be sorted.
Collections:
Collections module has some subclass of its as following:
- defaultdict: This is similar as dictionary, however, this is smarter than dictionary as if in case of any missing key in the dictionary, it creates the key and store the value for the key.
- orderedDict: This data structure keeps all entries sorted by the order of the insertion.
For example for a general collection as the following example:
hashtable = {} hashtable[1] = "Summer" hashtable[2] = "Fall" hashtable[3] = "Winter" for key, value in hashtable.items(): print (key, value)The output would be:![Collection Output]()
Another way of creating ordererdic is as following:
import collections hashtable = collections.OrderedDict( [(1, "Summer"), (2, "Fall"), (3, "Winter")] ) for key, value in hashtable.items(): print (key, value)
- Counter: This can count the occurrence of item in a collections. For example for the following code.
import collections Fav_seasons = ( ('John', 'Summer'), ('Smith', 'Winter'), ('Barak', 'Fall'), ('John', 'Fall'), ('Smith', 'Summer'), ('Ahmed', 'Autumn'), ) favseasons = collections.Counter(name for name, season in Fav_seasons) print (favseasons) #hashtable = {}John has 2 favorite seasons, Smith has 2 favorite seasons and Barak and Ahmed each has 1 favorite seasons, therefore, the output of this program would be:
![Python Collections Interview Questions]()
- Deque : This is a doubly linked queue. Therefpre , it is possible to add or remove items from the both end of the queue. Once interesting feature of deque is that it can be rotate, for example:
import collections d = collections.deque(range(10)) print('Normal :', d) d = collections.deque(range(10)) d.rotate(2) print('Right rotation:', d) d = collections.deque(range(10)) d.rotate(-2) print('Left rotation:', d)The output would be:
![Python Deque Interview Questions]()



What are Regular Expressions and how to use them in Python?
Regular expression is very important for data analysis and manipulation. Following table would introduce different sign used in python as well as all other programming language for regular expression.
| Symbol | Definition |
| ^ | matches the beginning of a string. |
| $ | matches the end of a string. |
| \b | matches a word boundary. |
| \d | matches any numeric digit. |
| \D | matches any non-numeric character. |
| (x|y|z) | matches exactly one of x, y or z. |
| (x) | in general is a remembered group. We can get the value of what matched by using the groups() method of the object returned by re.search. |
| x? | matches an optional x character (in other words, it matches an x zero or one times). |
| x* | matches x zero or more times. |
| x+ | matches x one or more times. |
| x{m,n} | matches an x character at least m times, but not more than n times. |
| ?: | matches an expression but do not capture it. Non capturing group. |
| ?= | matches a suffix but exclude it from capture. Positive look ahead. a(?=b) will match the “a” in “ab”, but not the “a” in “ac” In other words, a(?=b) matches the “a” which is followed by the string ‘b’, without consuming what follows the a. |
| ?! | matches if suffix is absent. Negative look ahead. a(?!b) will match the “a” in “ac”, but not the “a” in “ab”. |
| Flag | Description |
| re.I | Ignore case. |
| re.L | Matches pattern according to locale. |
| re.M | Enable multi line regular expression. |
| re.S | Make the “.” special character match any character at all, including a newline. |
| re.U | Matches pattern according to Unicode character set. |
| re.X | Ignore whitespace and treats unescaped # as a comment marker. |
Example: Validate Email Address
import re
email = abcdefg@gmail.com
email2 = abcdefg#gmail.com
k = false
if(re.match("^.+\\@(\\[?)[a-zA-Z0-9\\-\\.]+\\.([a-zA-Z]{2,3}|[0-9]{1,3})(\\]?)$", email != None):
k = true
q = false
if(re.match("^.+\\@(\\[?)[a-zA-Z0-9\\-\\.]+\\.([a-zA-Z]{2,3}|[0-9]{1,3})(\\]?)$", email2 != None):
q = true
print(k)
print(q)
The output would be:

Give some example of Functional programming in Python?
Here is an example of traditional square function in python:
def sqr(x):
return x*x
number = [1, 2, 3, 4]
output = []
for i in number:
output.append(sqr(i))Now in functional programming a function take and input and generate output without any intermediate step. If we rewrite the above function as following:
def sqr(x):
return x*x
number = [1, 2, 3, 4]
output = map(sqr, number)In python map, filter, reduce, lambda are used for functional programming.
Describe Python’s Exception Handling mechanism in brief?
| Exception Name |
Reason |
| Exception | Parent class of all exception. |
| StopIteration | If iterator has no next object to iterate. |
| SystemExit | If system exit abruptly. |
| StandardError | Parent class for all built-in exceptions except StopIteration and SystemExit. |
| ArithmeticError | When there is an error in numeric calculation. |
| OverflowError | Raised when a result of any numerical computation is too large. |
| FloatingPointError | Raised when a floating point calculation fails. |
| ZeroDivisionError | When there is a divition by 0 or module by 0 occur. |
| AssertionError | Raised in case of failure of the Assert statement. |
| AttributeError | Raised in case of failure of attribute reference or assignment. |
| EOFError | Raised when there is no input from either the raw_input() or input() function and the end of file is reached. |
| ImportError | When the module to be imported is not installed. |
| KeyboardInterrupt | Ctrl+C caused this interruption exception. |
| LookupError | Base or parent class for all lookup errors. |
| IndexError | Similar to ArrayIndexOutOfExcerption in Java. |
| KeyError | Dictionary is a container of list of (key,value) air. If the key is not found, this exception is raised. |
| NameError | Raised when an identifier is not found in the local or global namespace. |
| UnboundLocalError | Raised when trying to access a local variable in a function or method but no value has been assigned to it. |
| EnvironmentError | Base class for all exceptions which are outside the Python environment. |
| IOError | Raised when there is a file red/write error. Also raised for operating system-related errors. |
| SyntaxError | Raised for any error in Python syntax. |
| IndentationError | Indention is very important in python for each codde block. This error is raised when indentation is not correct. |
| SystemError | If Python interpreter finds an exception. This can be handled in code as the interpreter does not exit. |
| TypeError | Raised when any operation is intended to be executed on a wrong data type. |
| ValueError | Raised when type conversation can not occur due to wrong value. |
| RuntimeError | Raised when an unknown exception occur. |
| NotImplementedError | Raised when an abstract method that needs to be implemented in an inherited class is not actually implemented. |
Try-except-finally Block:
try:
// do some operation
except Error1:
// catch exception of type Error1
except Error2:
// catch exception of type Error2
else:
// execute this block when no exception is occurred
finally:
// the final block excute at the end of try and except either there is an exception or notNested Try-except Block:
try:
// do some operation
try:
// this is the nested try block
except Error1:
// catch exception of type Error1 for nested try
else:
// execute this block when no exception is occurred
finally:
// the final block excute at the end of try and except either there is an exception or not
except Error2:
// catch exception of type Error2 for outer try block
else:
// execute this block when no exception is occurred
finally:
// the final block excute at the end of try and except either there is an exception or notTry Block without Except:
Each try block must be followed by either a except of finally block.
try: // execute some operation finally: // the final block excute at the end of try and except either there is an exception or not
Different Ways to Handle Exception in Python:
- Catch exception argument: Exception or can be handled with argument. As in following exception, ‘car’ can not be converted to int and args of error object define the reason for exception.
![Catch Exception Argument Question]()
- Multiple exception in same line.
try: # some operation in thos blcok except (Erro1[, Erro2[,...ErroN]]]): # if any exception from the list occur , this block would be executed else: If there is no exception then execute this block

Throw Exception:
Raise command is used to throw an exception either user defined or built-in as following:
- If the error type is not known, it is possible to catch all kind of exception.
![Throw Exception Interview Question]()
- It is also possible to detect which kind of error has been raised.
![Detect Error Type]()
- It is also possible to pass user defined argument for the thrown exception.
![User Defined Argument]()



How Object Serialization works in Python?
Object serialization is a simple way to convert an object from format to others and at the same way later this converted form of object can be converted back to the earlier version of object. Python uses a particular mechanism in order to serialize object which is known as ‘pickling’. Using pickling an object can be converted to a binary object.
There are two steps in order to serialize an object:
- Import the pickling module.
- Call the dump method with the object as an argument.
import pickle class User: def __init__(self, name, age): self.name = name self.age= age class John(User): def __init__(self, aget): John.__init__(self, “John”, color) john = Jhon(18) smith = pickle.dumps(john)
Here john and smith are two different type of object. Picling has been used to convert john to smith.
Similarly, way it is also possible to de-serialize the object:
John2 = pickle.loads( smith)
If we only want to convert any python object to json , there are the following two steps need to be executed:
- Import JSON module.
- Call dumps function from JSON module and pass the object as an argument.
import json d = [{"name":"John", "age":"10"}, {"name":"Smith", "age":"15"}] e = json.dump(d) print ("json version", d)
Here, the python object has been serialized to a json variable , the output would be as following:
Describe Object Oriented feature in Python?
There are two main concept of object oriented programming language. Python also support them.
- Inheritance
- Polymorphism
Inheritance:
Any class can be extended from another class. And the child class can access the method of the parent class.
Following are some example of method access across parent class and child class.
class Fruit:
def __init__(self, name, color):
self.__name = name # __name is private to Fruit class
self.__color = color
def getColor(self): # getColor() function is accessible to class Car
return self.__color
def setColor(self, color): # setColor is accessible outside the class
self.__color = color
def getName(self): # getName() is accessible outside the class
return self.__name
class Apple(Fruit):
def __init__(self, name, color, taste):
# call parent constructor to set name and color
super().__init__(name, color)
self.__taste = taste
def getDescription(self):
return self.getName() +" tastes "+ self.__taste + " is " + self.getColor() + "in color"
c = Apple("Red Apple", "red", "sweet")
print(c.getDescription())
print(c.getName()) # apple has no method getName() but it is accessible through class Fruit
class GreenApple(Apple):
def __init__(self, name, color, taste, typed):
# call parent constructor to set name and color
super().__init__(name, color, taste)
self.__typed = typed
def getTyped(self): # getTyped() is accessible outside the class
return self.__typed
g = GreenApple("Green Apple", "red", "sweet",2)
print(g.getDescription()) # greenapple has no method getDescription() but it is accessible through class Apple
print(g.getName()) # greenapple has no method getName() but it is accessible through class Fruit
print(g.getTyped())
The output would be as following:
Polymorphism:
In this following class diagram, both Window and Wall are of Structure type. Therefore, for both of them Structure is the parent class.
So now if we run the following example:
The output would be as following:
As the destroy method has not been implemented in the child classed in Window or Wall therefore, there is an exception has been thrown. Now if the program is fixed and all the abstract methods are implemented as following the output would be:
class Structure:
def __init__(self, loadbearing):
self.loadbearing = loadbearing
def built(self):
raise NotImplementedError("Subclass must implement abstract method")
def destroy(self):
raise NotImplementedError("Subclass must implement abstract method")
class Window(Structure):
isOpen=False;
def close(self):
self._isOpen =False;
def open(self):
self._isOpen =True;
def built(self):
return 'Wall has been built properly with loadbearing.'
def destroy(self):
return 'Wall has been destroyed properly.'
class Wall(Structure):
def built(self):
return 'Wall has been built properly.'
def destroy(self):
return 'Wall has been destroyed properly.'
structures = [Wall(True),
Wall(False),
Window(True)]
for structure in structures:
print (structure.loadbearing)
print(structure.built())
print(structure.destroy())
if isinstance(structure, Window):
print(structure.isOpen)
structure.open()
print(structure.isOpen)

The course is designed to cover web, database, data science, web scrapping, image processing, web visualization and much more.
Followings are few highlight about this Python Online Course:
- Best Seller Udemy Online Course
- 40,016++ students enrolled
- 6,251 Review available
- 23 Hours on-demand videos
- 28 Articles
- 36 Supplemental Resource
- Access on Mobile and TV
- Certificate of Completion
- Lifetime Access
- 30 days Money back guarantee
- You can get the course at Discounted Price here.
Most attractive feature is 30 days Money Back Guarantee means there is NO RISK. If you didn’t like this Python Online Course, you can refund your money back within 30 days of purchase.

We will soon add a small Online Test to enhance user skills. Keep in touch.
More Python and Related:
- Python for Data Science and Machine Learning Bootcamp
- Python and Django Full Stack Web Developer Bootcamp
- Angular 2 Interview Questions and Answers
- Machine Learning A-Z: Hands-On Python & R In Data Science
- MUST Have Bootstrap Interview Questions
- Python Game Development – Create a Flappy Bird Clone
- Python Certification Training
The post MUST Have Python Interview Questions – Part 2 appeared first on Web Development Tutorial.