This C# Tutorial Part-2 in series of C# Interview Questions with practical and detailed answers. In previous part, we covered many basic to intermediate level interview questions on C# with the help of practical examples. I’ll recommend strongly to go through part-1 in this series. We will continue this series to provide more practical details with real time scenarios and complete source code to grasp C# language concepts. But this time, we are understanding in a different way by comparing different concepts.
C# Interview Questions PDF version will be available later for download.
Following Technical Interview Questions and Answers will also be helpful.
- C# Interview Questions – Part-1
- ASP.NET Interview Questions Part-1 [Basics, Controls, State Management]
- ASP.NET Interview Questions Part-2 [Advanced Controls, Globalization and Localization]
- ASP.NET Interview Questions Part-3 [Caching & Security etc.]
- ASP.NET Interview Questions Part-4 [Advance Security]
- ASP.NET Interview Questions Part-5 [ASP.NET AJAX]
- ASP.NET Interview Questions Part-6 [ASP.NET Web API]
- ASP.NET MVC Interview Questions
- Entity Framework Interview Questions

Complete C# Interview Questions List
- Managed Vs Unmanaged Code
- Struct Vs class
- Abstract Vs Interface
- Boxing Vs Unboxing
- Method Overloading Vs Method Overriding
- Break and Continue Statements
- Constant Vs Read-Only
- Ref and out parameters
- String Vs String Builder
- Array.copyTo() Vs Array.Clone()
- Dispose and Finalise methods
- Late binding Vs Early binding
- IEnumerable & Iqueryable
- Throw Exception Vs Throw Clause
- == Vs equals
- Is Vs as operator
- Array Vs Array List
- Directcast Vs ctype
- Public Vs Static Vs void
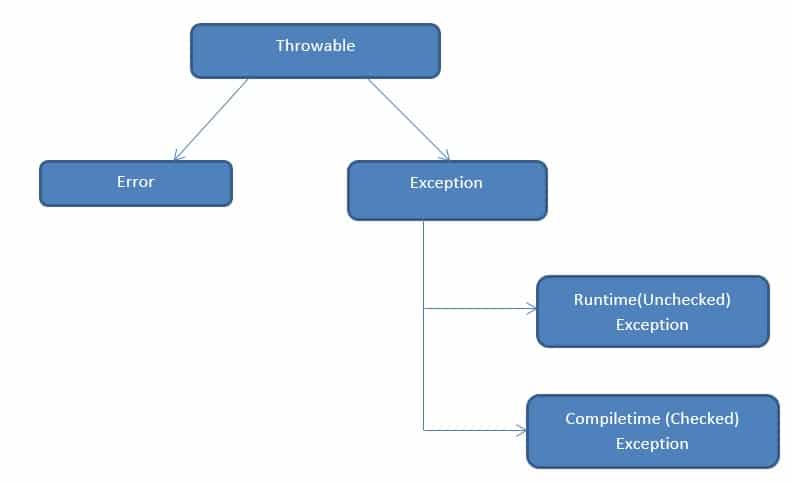
Managed Vs Unmanaged Code
Managed Code:
The code (like Vb.Net,C#,J#) which is written in .Net Framework and developed by .Net Framework and under the control of CLR(Common Language Runtime). And the garbage collector run automatically in managed code.
Unmanaged Code:
The code which is developed outside of the .Net framework is called unmanaged code. Unmanaged code does not run under the control of CLR. Unmanaged code executed with help of wrapper class CCW (COM Callable Wrapper) and RCW(Runtime Callable Wrapper). C++ can be used to write such application.
Struct Vs class
Structs and classes are the template or blue print that is used to create an object of a class.
| Class | Struct |
| Classes can be inherited | Structs are not inherited |
| Classes are reference type | Structs are value type |
| It could be null | It could not be null |
| Class can be abstract | It cannot be abstract |
| You can override the method within class | You cannot override the method within Struct |
- A struct always contain public default parameter less constructor it can not contain the private parameter less constructor.
struct A { private A() // compile time error { } } class B { private B() // run successfully } - Static constructor is triggered in case of class but not in case of structure.
struct A { static A() { Console.WriteLine("This is Constructor A()"); } } class B { static B() { Console.WriteLine("This is Constructor B()"); } } class Program { static void Main(string[] args) { //Nothing happen A a =new A(); //Will out put This is me a class B b=new B(); Console.Read(); } }Output: This is Constructor B()
Abstract Vs Interface
Abstract class and interface both are used to achieve abstraction (for hiding the functionality). Both contain the abstract method.
| Abstract Class | Interface |
| Abstract class contain both abstract and non-abstract method | Interface contain only abstract method |
| It contain final, non-final,static,non-static variable | It contain only static and final variable |
| Abstract class provides the implementation of interface | It cannot provide implementation of abstract class |
| It does not support multiple inheritance | Interface supports multiple inheritance |
| Abstract keyword is used to declare abstract class | Interface keyword is used to declare the interface |
Example of an Abstract class:
namespace ConsoleApplication
{
abstract class A // contain method body
{
public int add(int a,int b)
{
return a+b;
}
}
class B : A //classs B extends class A
{
public int mul(int a,int b)
{
return a*b;
}
}
class TestMain
{
Static void Main(string[] args)
{
B ob=new B();
int result=ob.add(5,10);
Console.WriteLine(“result {0}”,result);
Console.ReadLine();
}
}
}
Example of Interface:
namespace ConsoleApplication
{
interface A // can not contain method body
{
void method(); //public abstract by default
}
class B : A // class B implements interface A
{
Void mehtod()
{
Console.WriteLine(“Hello Welcome”);
Console.ReadLine();
}
Static void main(string[] args)
{
B ob=new B();
ob.mehod();
}
}
}
Back to top
Boxing Vs Unboxing
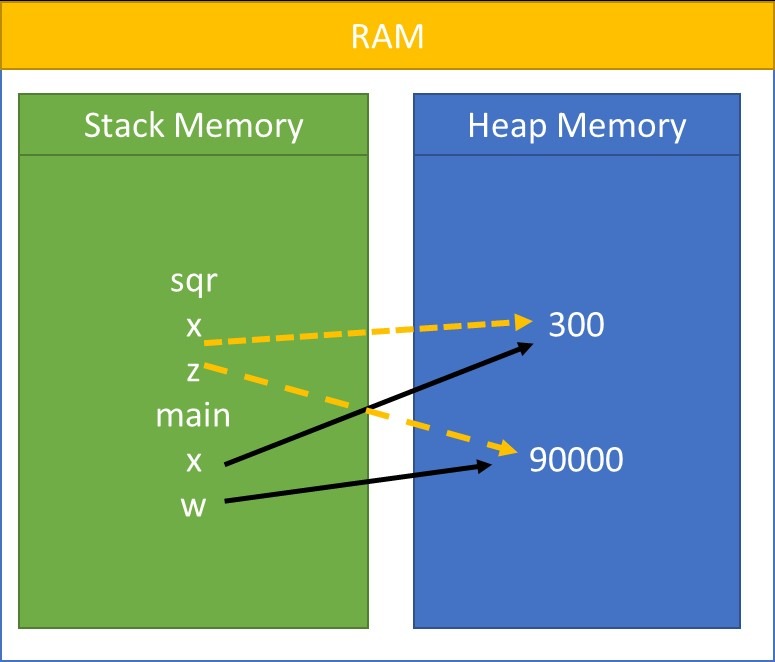
In C# there is three types of data type Value type,Reference Type and pointer type. The process of the converting a value type into reference type is called Boxing. While the Reference type is converting into value type called unboxing.
Int a=5; Object obj=5; //Boxing Int a=(Int)obj; //Unboxing
Example of Boxing and Unboxing:
namespace ConsoleApplication1
{
internal class Program
{
private static void Main(string[] args)
{
double a;
object ref;
a = 100;
ref = a; //Boxing - Value type to Object
double result = (double)ref; // UnBoxing - Reference Type to Value
Console.WriteLine(Result); // 100
Console.ReadLine();
}
}
}
Method Overloading Vs Method Overriding
| Method Overloading | Method Overriding |
| Method Overloading is used for increasing the code readability | Method Overriding is used for code re-usability |
| Parameter must be different | Parameter must be same |
| It can perform within the class | It occurs in two classes using inheritance (parent and child class) |
| It perform compile time polymorphism | It perform runtime polymorphism |
| No special keyword to use for method overloading. It can perform simply within the class. | Using virtual keyword with the base class method and override keyword with derived class method can achieved method overriding. |
Example of Method Overloading:
namespace ConsoleApplication
{
class Calculation
{
public void add(int a,int b)
{
Console.WriteLine(a+b);
}
public void add(int a,int b,int c)
{
Console.WriteLine(a+b+c);
}
}
class TestMain
{
static void Main(string[] args)
{
Calculation ob=new Calculation();
ob.add(5,10);
ob.add(5,10,15);
}
}
}
Example of Method Overriding:
namespace ConsoleApplication
{
class A
{
public virtual void Method() // Virtual method
{
Console.WriteLine("This is the Base Class");
}
}
class B : A
{
public override void Method() // Overriding virtual method
{
Console.WriteLine("This is the Derived Class");
}
}
class TestMain
{
static void Main()
{
B ob=new B();
ob.Method();// output: This is Derived Class
}
}
}
Back to top
Break and Continue Statements
Break statement is used to break out of loop that’s mean you can jump out of loop at the current position and it terminate the loop.
Continue statement is used to (one iteration) jump over one iteration and again it continues the loop.
namespace ConsoleApplication
{
class A
{
static void Main(string[] args)
{
int i;
for (i = 0; i <= 10; i++)
{
if (i == 4) // it jump out of loop where i==4 and start again from next value
continue;
if (i == 7) // iteration stoped when i==7 and terminate the program
break;
Console.WriteLine(i);
}
Console.ReadLine();
}
}
}
Output:
0
1
2
3
5
6
Constant Vs Read-Only
Constant and Read-only is the keyword that is used to make the field constant that can not be modified.
Constant Value:
Constant variable or local variable are assigned at the time of declaration they cannot be modified after the declaration. Constant variables are static by default hence you cannot use static keyword with the constant field (or variable).
public const int a=1;
ReadOnly:
A read-only field can be assigned either at the time of declaration or inside the constructor of the same class, that’s why read only field can be used run-time constant.
class A
{
readonlyint a=1;
readonlyint b
public A(int a)
{
this.a=a;
}
}
Ref and out parameters
Ref and out parameters are used to pass an argument into a method. By using this parameter you can return more than one value.
In the case of ref parameter first you need to initialize it then pass to the method but for out parameter, you don’t need to initialize.
Ref:
The ref keyword is used to pass an argument as a reference. When the value of that parameter will be changed in the method, it will be reflected in the calling method.
It needs to be initialized before passing into the method.
class A()
{
Static void Main()
{
Int a; //need to be initialised
a=1;
method(ref a)
Console.Write(a);
}
public static void method(ref int b)
{
B+=5;
}
}
Output: 6
Out:
The out keyword is used to pass an argument same as ref keyword but in the case of out ref, you can pass the argument without assigning the value. Instead, it must be initialized in the called method before it returns back to the calling method.
class A
{
Static void Main()
{
Int a,b; // no need to be initialised
Method(out a, out b)
Console.Write(a);
Console.Write(b);
}
Public static intmethod(out int n, out int m)
{
n=2;
m=5;
return 0;
}
}
Output:
2
5
String Vs String Builder
String:
String is Reference type data type, you cannot insert, modify or delete any data when a string is created that means in simple word we can say that string is an immutable means once you created the object of string you cannot modify it when you try to modify it will create a new object in memory.
String s1= “Hello Jackson”; String s1=”Hye Jackson”; // created a new object
String Builder:
String Builder is an object of string to work with string we have to use a namespace(“Using System. Text) so unlike string, a string builder is an object and we can apply insert, modify and remove function in string builder without creating a new object, It will automatically update in memory does not create new space in memory. We can also say that string builder is mutable that’s mean changeable.
StringBuildersb=new StringBuilder(); sb.append(“Hello jackson”); sb.replace(“hiijackson”); //updating string memory
Array.copyTo() Vs Array.Clone()
Array.copyTo () and Array. Clone() both areused to replicate the element of existing Single dimension array.
Array.copyTo:
Array.copyTo () method copy the array’s element into existing/destination array with the reference of targeted instance of existing/destination array. You can say that Array.copyTo allows to replicate the into specified index.
Array.Clone():
Array. Clone () replicate the existing element array in the new array object containing all element of exiting array without having any reference.
using system;
class copycloneexp
{
public static void Main()
{
Int[] existingarray=new int[3];
existingarray[0]=10;
existingarray[1]=15;
existingarray[2]=20;
Int[] destinationarray = new int[existingarray.Length]
existingarray.CopyTo(destinationarray,0);
int[] destinationarray1;
destinatioarray1=existingarray.CloneTo() as int; // exp of array.cloneto()
}
}
Dispose and Finalise methods
Memory management is a big challenge when you are developing a web Application/software as we know that Garbage Collector plays the main role in .Net to manage unmanaged resource and Dispose and finalize method both are part of Garbage Collector.
Dispose and finalize method both are used to reclaim the memory used by the unmanaged resource.
| Dispose method | Finalize method |
| Unlike Finalize method it is not directly called by GC, User has to write code to implement it. | Finalized method is automatically called by GC when any resource goes out of scope or at end of program. |
| It is a faster method and called by the user for instant object disposal. | It is a slower method and automatically called by GC at end of,User can only override method when indeed. |
| Dispose method is the part IDisposable interface in GC | Finalize method is the part of object class in GC |
using System;
using System.Diagnostics;
public class A
{
Stopwatch watch;
public A()
{
watch = Stopwatch.StartNew();
Console.WriteLine("Instantiated object"); // Instantiated object
}
public void ShowDuration()
{
Console.WriteLine("This instance of {0} has been in existence for {1}",this, sw.Elapsed);
}
~A()
{
Console.WriteLine("Finalizing object"); // Finalizing object
sw.Stop();
Console.WriteLine("This instance of {0} has been in existence for {1}",
this, sw.Elapsed);
}
}
public class Demo
{
public static void Main()
{
AClass ob = new AClass();
ob.ShowDuration();
}
}
Back to top
Late binding Vs Early binding
If the methods have same name and different parameter declare in a single class or methods have same name and same parameter but declare in different classes then it is called Binding or Polymorphism.
Late Binding:
It is also called runtime polymorphism; the situation arrives when methods are virtual and have same name and same parameter in different classes (must be derived class). Then it is called method overriding or late binding.
using System;
public class Vehicle
{
public virtual void run()
{
Console.WriteLine("Running...");
}
}
public class Bike: Vehicle
{
public override void run()
{
Console.WriteLine("Bike is running safely...");
}
}
public class TestMain
{
public static void Main()
{
Vehicle a= new Bike(); // object id determined at runtime
a.eat();
}
}
Output: Bike is running safely
Late Binding:
It is also called compile time polymorphism; the situation arrived when methods have same name but different parameter in same class.
It is also called method overloading.
using System;
public class A
{
public void Sum(int a, int b)
{
Console.WriteLine(a + b);
}
public void Sum(int a, int b, int c)
{
Console.WriteLine(a + b + c);
}
static void Main(string[] args)
{
A ob=new A(); // Object is determined at compile time
ob.Sum(5,8);
ob.Sum(5,8,10);
}
}
IEnumerable & IQueryable
IEnumerable and IQueryable are used for data manipulation in LINQ from the database and collection.
| IEnumerable | IQueryable |
| It exists in System. Collections Namespace | It exists in System.Linq Namespace |
| It is the best for query data from in memory collections like List, Array etc. | It is best for query data from out-memory (like remote database, Service) collection. |
| It execute select query on server side, load data in memory on client side and then filter data. | It executes select query on server side as well as filtered there. |
| Suitable for LINQ or Object and LINQ to XML queries | Suitable for LINQ to SQL queries |
| It does not supports the custom query | It supports custom query using Create Query and Execute method |
| It supports lazy loading that’s why suitable for paging | It does not support lazy loading that’s why not suitable for paging |
using System;
using System.Collections.Generic;
using System.Reflection;
using System.Collections;
namespace TesIEnumerable
{
class A
{
public static void Main(String[] args)
{
IEnumerable<int> data = from value in Enumerable.Range(1, 10) select value;
foreach (int a in data)
{
Console.WriteLine(a);
}
Console.ReadLine();
}
}
}
Output:
1
2
3
4
5
6
7
8
9
10
Back to top
Throw Exception Vs Throw Clause
| Throw Exception | Throws Clause |
| It is used to throw an exception explicitly | It is used to declare an exception |
| It is used inside the method body to invoke an exception. | It is used in method declaration(signature) |
| You cannot throw more than one exception | You can throw multiple exceptions |
| Follow by instance variable | Follow by exception class name |
Throw Exception Example:
static
{
try
{
throw new Exception(“Logical Error”);
}
catch(Exception ex)
{
console.WriteLine(“Error:” + ex.geMessage())
}
}
Throws Clause Example:
public void method() throws ArithmeticExeption
{
ArithmeticExeption ex = new ArithmeticException();
throw ex;
}
Back to top
== Vs equals
The == operator compare the reference of the object while the equals compares the contents of the object see the bellow example.
namespace ConsoleApplication6
{
class Program
{
static void Main(string[] args)
{
Object o1 = "Sachin";
char[] c={'S','a','c','h','i','n'};
Object o2 = newString(c);
Console.WriteLine(o1==o2); //compare the reference
Console.WriteLine(o1.Equals(o2)); // compare the contents
Console.ReadKey();
}
}
}
Output:
False
True
Is Vs as operator
Is operator is used to checking the Object type and it returns the Boolean value true if the object is same otherwise returns false.
The as operator perform the conversions between compatible types.it is also work similar as Is operator but instead of return Boolean value it returns the object if they are compatible type otherwise returns null.
Example of Is Operator:
class A
{}
class B : A
{}
public class IsOperator
{
static void Main()
{
A a = new A();
B b = new B();
Console.WriteLine(a is A);
Console.WriteLine(a is Object);
Console.WriteLine(b is A);
Console.WriteLine(a B);
}
}
Output:
True
True
True
False
Example of as Operator:
using System;
class A {}
class B : A {}
public class AsOperator
{
static void Main()
{
object[] objects = new object[6];
objects[0] = new A();
objects[1] = new B();
objects[2] = "Hello";
objects[3] = 12;
objects[4] = 1.4;
objects[5] = null;
for (int i=0; i<objects.Length; ++i)
{
string str = objects[i] as string;
Console.Write ("{0}:", i);
if (str != null)
Console.WriteLine (str);
else
Console.WriteLine ("not a string");
}
}
}
Output:
0: not a string
1: not a string
2: Hello
3: not a string
4: not a string
5: not a string
Back to top
Array Vs Array List
| Array | Array List |
| Array is collection of similar data types that’s mean we can store only one data type either Int,string,char….etc. | Array List is the collection of different data types that’s mean we can store all data types in array list. |
| The length of array is fixed | Array list can decrease or increase dynamically as per usage |
| Array belongs to System. Array namespace | It belongs to System. Collection namespace |
Array Example:
namespace Example1
{
class ArrayExample
{
static void display(int[] array)
{
Console.WriteLine("Elements of array are:");
foreach (int i in array)
{
Console.Write("\t{0}", i);
}
}
static void Main(string[] args)
{
int[] arr = new int{25,15,5,10};
int i;
// loop for accepting values in array
for (i = 0; i < 4; i++)
{
arr[i] = Convert.ToInt32(Console.ReadLine());
}
ArrayExample.display(array);
//sorting array value;
Array.Sort(array); //use array's sort function
ArrayExample.display(array);
Console.ReadLine();
}
}
}
Output: Elements of array are:
5 10 15 25
ArrayList Example:
using System;
using System.Collections;
class Program
{
static void Main()
{
ArrayList list = new ArrayList(); // Create an ArrayList with four strings.
list.Add("USA");
list.Add("London");
list.Add("Brazil");
list.Add("India");
list.Sort(); // Sort the ArrayList.
foreach (string value in list)
{
Console.WriteLine(value);
}
list.Reverse(); // Reverse the ArrayList.
foreach (string value in list)
{
Console.WriteLine(“Reverse Arraylist…………..”)
Console.WriteLine(value);
}
}
}
Output:
Brazil
India
London
USA
Reverse Arraylist…………..
USA
London
India
Brazil
Back to top
Directcast Vs ctype
| Directcast | cType |
| Directcast is generally used to cast reference data type. | It is used to cast value type. |
| To perform the Directcast between two different classes, the classes should have relationship between them. | To perform ctype b/w two different value types, relationship is not required. If the conversion is legal it will be performed. |
| When you perform Directcast on arguments that do not match it will throw InvalidCastException. | Exception is not thrown while perform ctype. |
| Performance of Directcast is better than ctype because there is no runtime helper routines of VB.Net are used for casting. | It requires runtime helper routine of VB.Net hence performance is slow that Directcast. |
| Directcast is portable across many language that’s mean it is not specific to VB.Net | Ctype is not portable it is specific to VB.Net. |
Directcast Example:
Object exp = ”public keyword is access modifier”; String exp1 =(string) exp; Object exp2 = exp1; Object exp3 = (object) exp1;
Type Cast Example:
TextBox exptype=(TextBox)obj;Where obj is Typecast
Public Vs Static Vs void
Public: public keyword is access modifier and tells the c# compiler that the Main method is accessible by anyone.
Static: static keyword declared that the Main method is global and can call without creating an instance of the class.
Void: void keyword is used to specify that the Main method does not return any value.
Example of public and static keyword:
using System;
namespace staticexample
{
class A
{
public static int a; // static variable can be initialised out side of member function
public static void display() // static and void method means no return type
{
a=10;
Console.WriteLine(a);
}
public void demo() // public and void method means non return type
{
int b=20;
Console.WriteLine(b);
}
static void Main(string[] args)
{
A obj = new A();
A.display(); //calling display method through class name
obj.demo(); //calling demo method using instance of class
Console.Read();
}
}
}
Output: 10
20
Back to topTop Technical Interview Questions and Answers Series:
- Top 20 AngularJS Interview Questions
- Advanced Angular2 Interview Questions
- Top 15 Bootstrap Interview Questions
- ReactJS Interview Questions and Answers
- Top 10 HTML5 Interview Questions
- Must Have NodeJS Interview Questions
- BackboneJS Interview Questions
- Top 10 WCF Interview Questions
- Comprehensive Series of WCF Interview Questions
- Java Spring MVC Interview Questions
Top C#.NET Jobs [Updated Daily]
|
ASP.NET Developer, 100% remote
|
Remote | 23-January-2017 |
|
Senior .Net Developer
|
Redmond, WA | 06-April-2017 |
|
Senior Web Developer
|
Rocky Mount, NC | 07-April-2017 |
|
Senior Full Stack .NET Web Developer
|
Beaverton, OR 97005 | 04-April-2017 |
|
Senior Web/Application Developer
|
Troy, OH 45373 | 30-March-2017 |
|
.NET Developer Web (mid-level to senior)
|
Norcross, GA 30071 | 22-March-2017 |
|
Application Developer
|
Lansing, MI 48911 | 06-April-2017 |
|
Microsoft Application Developer
|
Rosemont, IL 60018 | 01-April-2017 |
|
Senior Software Developer .NET ASP.NET MVC
|
New York, NY 10006 | 31-March-2017 |
|
Senior Web Developer
|
Boston, MA 02116 | 09-March-2017 |
|
.Net Application Developer
|
St. Louis, MO | 27-March-2017 |
|
Software Application Developer
|
Cincinnati, OH 45241 | 25-March-2017 |
|
Sr. Application Developer (C#, Angular.JS, Linq)
|
Allentown, PA | 24-March-2017 |
|
Full Stack Developer
|
Everett, WA | 29-March-2017 |
|
Mobile Application Developer
|
Atlanta, GA | 21-March-2017 |
|
Senior-Level Software Application Developer
|
Nashville, TN 37203 | 17-March-2017 |
|
Mid to Senior level Demandware Developer
|
San Francisco, CA | 16-March-2017 |
|
Senior Software Engineer
|
Canton, OH | 07-April-2017 |
|
Senior Software Engineer, Ed-Fi Alliance - Austin, TX
|
Austin, TX 78746 | 07-April-2017 |
|
Senior Full Stack Software Engineer
|
Austin, TX 78759 | 07-April-2017 |
|
Senior Full Stack Developer
|
Modesto, CA | 13-March-2017 |
|
Web Developer
|
Redmond, WA | 05-April-2017 |
|
Senior C#/.NET Full Stack Developer
|
Beaverton, OR 97008 | 09-March-2017 |
|
Lead .NET Developer – loan origination
|
Dallas, TX 75235 | 08-April-2017 |
|
Senior .NET Software Engineer
|
Maitland, FL | 30-March-2017 |
The post MUST Have C# Interview Questions and Answers – Part 2 appeared first on Web Development Tutorial.











 If every things goes fine then, console will show waiting for connections, which indicates that mongodb has been installed and configured successfully.
If every things goes fine then, console will show waiting for connections, which indicates that mongodb has been installed and configured successfully.



 Lets say we want to check the list of database, we will use the show dbs command. Below is the syntax for the same.
Lets say we want to check the list of database, we will use the show dbs command. Below is the syntax for the same.












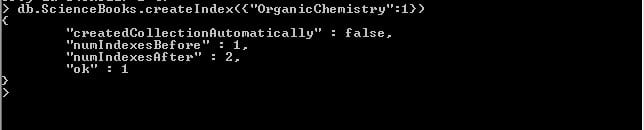


 As we can see, the output of find command displayed all records of ScienceBooks collection. Now I want to have projection in place and want to see only name and not _id. Lets see how we can achieve this:
As we can see, the output of find command displayed all records of ScienceBooks collection. Now I want to have projection in place and want to see only name and not _id. Lets see how we can achieve this:





 Lets try to store this file using GridFS.
Lets try to store this file using GridFS.


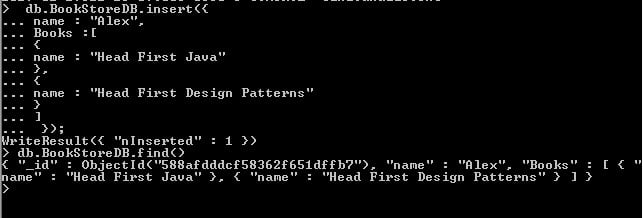





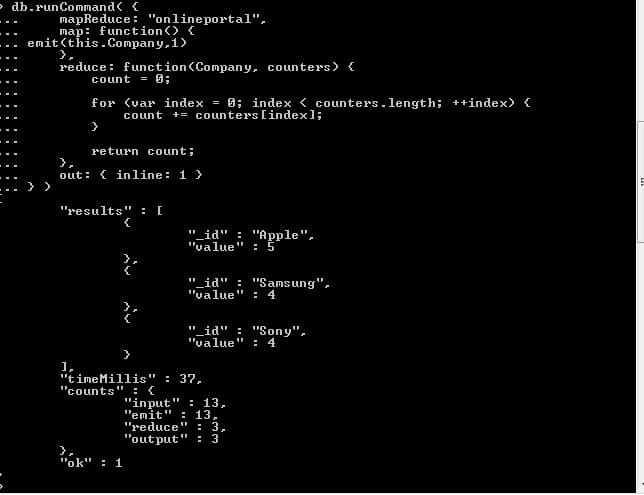


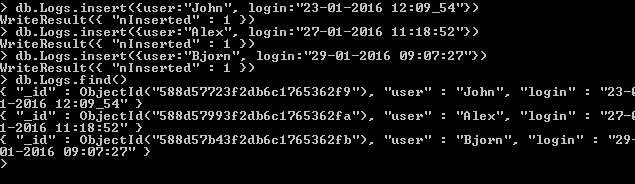





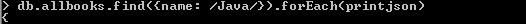 This is all about pattern matching using regex in MongoDb.
This is all about pattern matching using regex in MongoDb.















 With a whopping 2.8 million apps in the Android store, we all can wonder how difficult it is for people who are trying to make a mark in the Android app store. The more the number of options users have in front of them, the stiffer the competition grows for these app developers.
With a whopping 2.8 million apps in the Android store, we all can wonder how difficult it is for people who are trying to make a mark in the Android app store. The more the number of options users have in front of them, the stiffer the competition grows for these app developers.


 Once the download is complete, execute the installer and once the installation s complete, open a terminal and run the following command.
Once the download is complete, execute the installer and once the installation s complete, open a terminal and run the following command.